对于XXL-JOB 的使用和功能介绍在其文档中非常清晰,且非常容易上手,本篇文章是把官方文档众多内容简单梳理后而成,目的在于尽可能简单清晰用通俗化的语言把XXL-JOB 工具介绍给一个小白用户。
什么是分布式任务调度
在日常开发中,可能会碰到类似「每天定时推送一些业务数据通知到用户」的场景,这时能想到最简单的解决方案时用JDK定时任务的Timer。但随业务发展,单 体应用不仅有挂掉的风险,且不一定能Hold大量的业务数据。这时最简单的方法就是加机器(横向扩展),这也带来了很多问题。
- 分布式:怎么保证任务正确的执行:比如5台机器,同一时间只要1台机器执行
- 故障处理:机器在执行任务的时候挂掉了怎么办?
- 任务管理:如果有几千个任务该如何管理?
- 日志监控:怎么知道任务的执行情况?
等等多个问题。
而分布式调度平台的产生就是去解决以上问题。目前比较知名的几个分布式任务调度平台有:Quartz、ElasticJob、LTS(Light Task Scheduler)、XXL-JOB.XXL-JOB 简介
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
该工具的开发者是来自美团点评的许雪里,XXL是作者名的缩写而成。
亮点
文档介绍几十个特性,这里我摘选几个比较重要的亮点特性:
- 中心化架构:和ElasticJob和LTS去中心化架构不同,XXL-JOB是中心化架构,由调度中心和执行器组成。
- 后台管理WEB:管理页面可以管理执行器、CRUD任务、查看调度日志和任务日志
- Rolling实时日志:支持在线查看调度结果,并且支持以Rolling方式实时查看执行器输出的完整的执行日志;
- GLUE:提供Web IDE,支持在线开发任务逻辑代码,动态发布,实时编译生效,省略部署上线的过程。支持30个版本的历史版本回溯。
- 任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔;
- 路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
- 全异步:任务调度流程全异步化设计实现,如异步调度、异步运行、异步回调等,有效对密集调度进行流量削峰,理论上支持任意时长任务的运行;
运行部署的几个步骤
文档中的「快速入门」已经非常具体了。大概分为
- 初始化调度数据库
- 部署调度中心集群:xxl-job-admin
- 部署执行器集群:xxl-job-core。可以直接使用,也可以将现有项目改造为执行器,只要引入
xxl-job-core的Maven依赖即可。
- 登录调度中心访问地址,管理配置。
注意:本篇运行部署的版本是v2.12架构
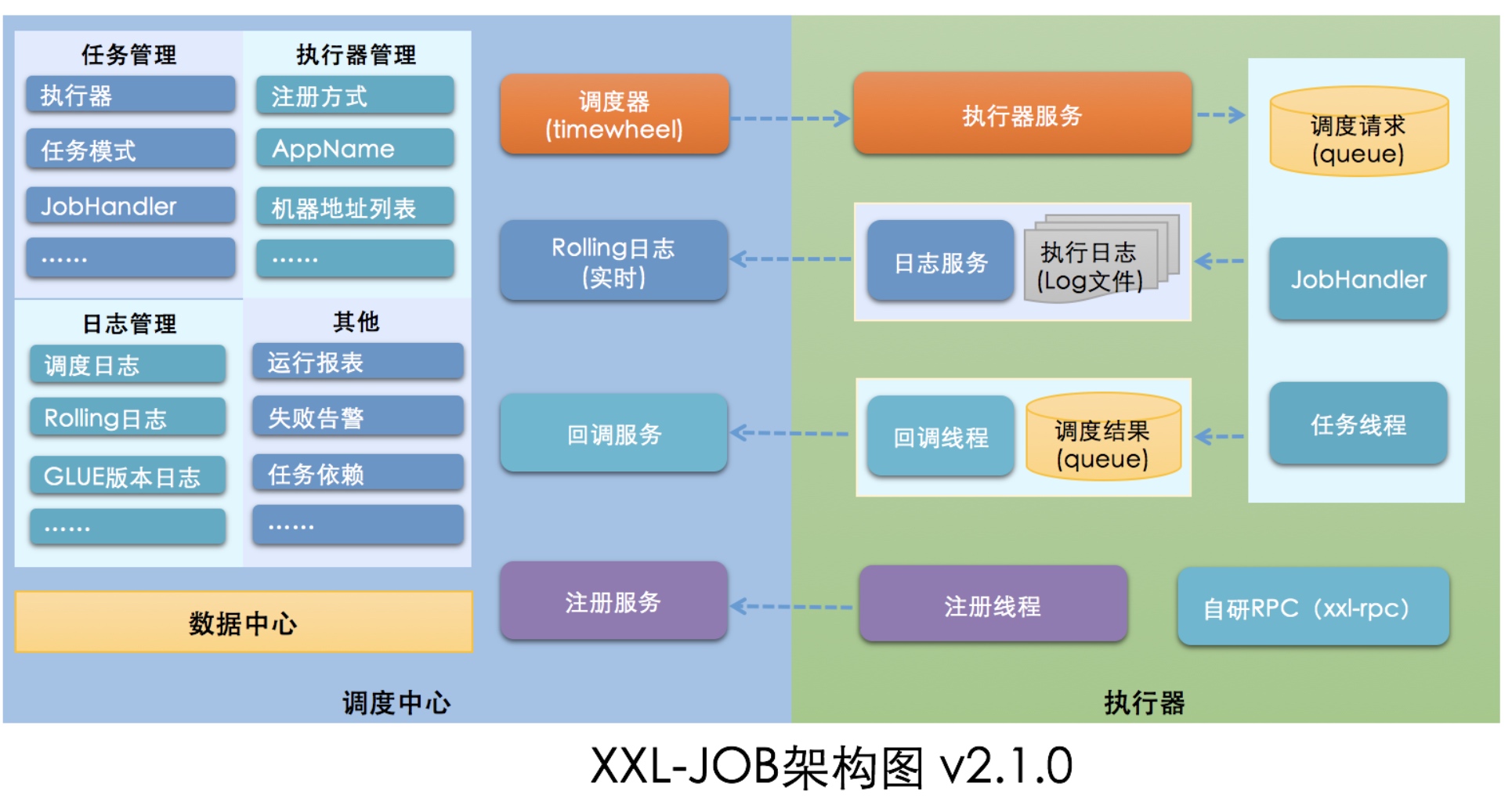
从架构图上理解,XXL-JOB分为两个部分,同时也对应两个项目。
- 调度中心(xxl-job-admin)
- 执行器(xxl-job-core)
- 主动注册
- 任务执行
- 任务回调
- 日志服务
同时,从架构图也可以看出来基本的工作执行流程如下:
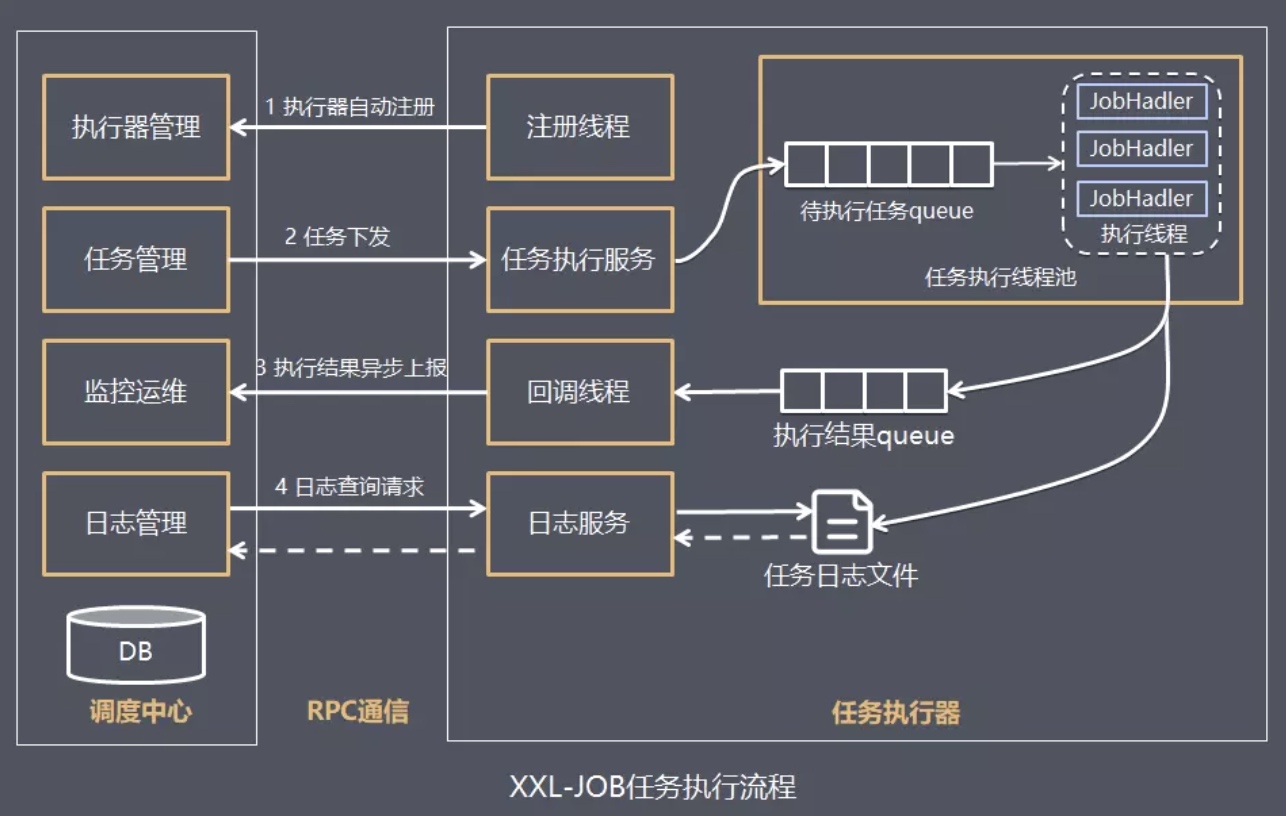
- 任务执行器根据配置的调度中心的地址,自动注册到调度中心
- 达到任务触发条件,调度中心下发任务
- 执行器基于线程池执行任务,并把执行结果放入内存队列中、把执行日志写入日志文件中
- 执行器的回调线程消费内存队列中的执行结果,主动上报给调度中心
- 当用户在调度中心查看任务日志,调度中心请求任务执行器,任务执行器读取任务日志文件并返回日志详情
统一术语
- 调度中心:负责管理、调度、监控任务的全周期。可以理解为所有执行器的老大,所有的执行器都有老大调遣;
- 执行器:可以理解为具体干活的一类小弟,小弟要主动去认老大(自动注册),老大发出指令后执行(任务执行),执行后反馈任务执行结果(回调线程),同时也提供给老大查询任务执行过程记录的能力(日志服务);
- 任务:一件事情,由一个或一组执行器执行;
- 调度:老大交给小弟办一件事的具体描述;
注册方式:自动注册和手动录入
在调度中心的执行器管理页面,提供了两种执行器注册方式。
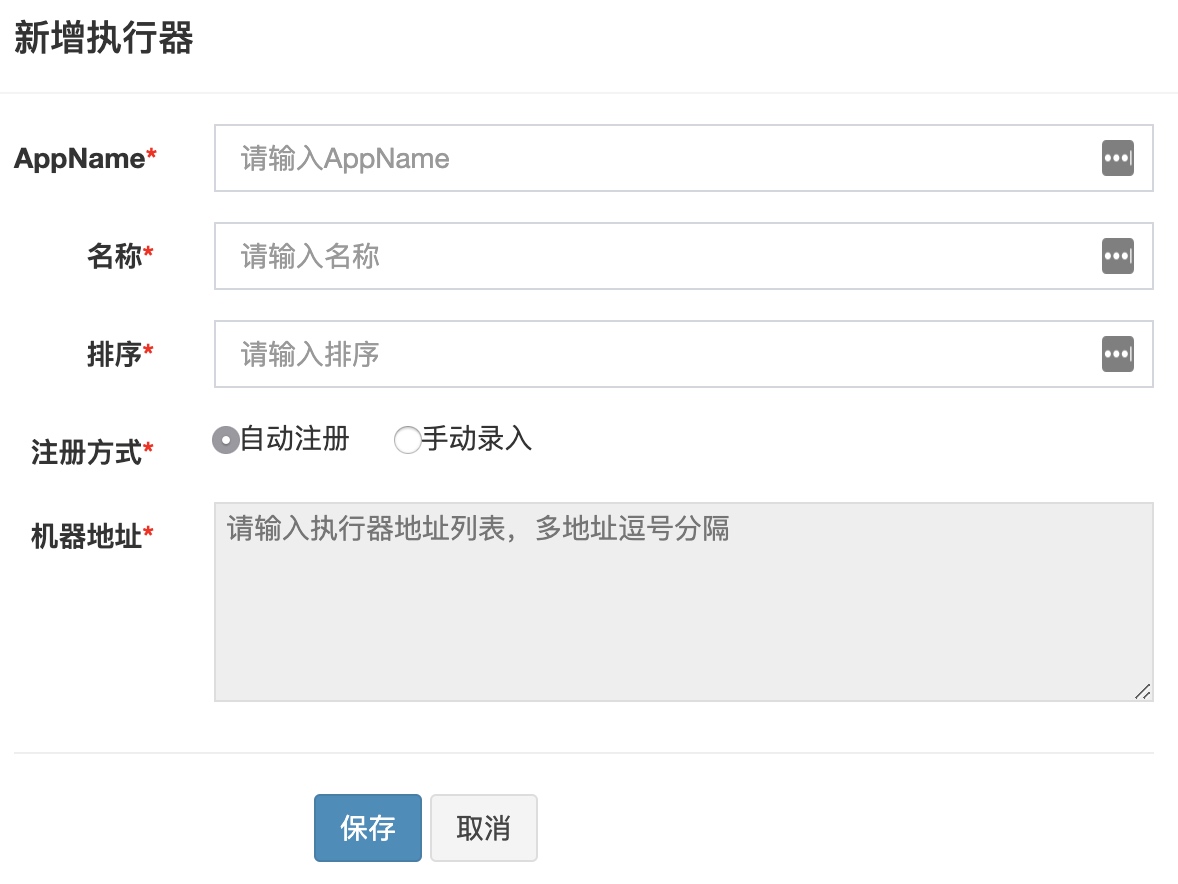
这里需要明白4个字段的含义:
- 执行器:这里的执行器实际指的是「执行器集群」的概念,并非单个机器节点,同时这也是执行任务的基本单位,也就是说调度中心并不能「直接」指定某台机器去执行任务,但可以「间接」通过定义任务路由的方式实现;
- AppName:「执行器集群」的唯一标志,每个执行器机器集群的唯一标示, 任务注册以 “执行器” 为最小粒度进行注册; 每个任务通过其绑定的执行器可感知对应的执行器机器列表;
- 注册方式:分为自动和手动,如果是自动就不用填机器地址,同时执行器配置要必填调度中心地址和AppName用于主动注册;如果是手动,需要填写机器地址;
- 机器地址:具体执行任务的机器节点。一个AppName维护着包含多个机器节点的列表;
无论是自动注册还是手动注册,都需要用户在执行器管理页面声明一个执行器,这里我们着重说一下自动注册的配置和流程。主动注册配置说明:
- 首先需要在执行器管理页面新建一个注册方式为「自动注册」的执行器;
- 部署执行器时需要填写
xxl.job.admin.addresses和xxl.job.executor.appname两个配置字段表明开启自动注册,这两个字段时选填的,如果为空则表明关闭自动注册;执行器注册和摘除流程说明:
任务注册的心跳周期Beat默认为30s。
- 执行器节点启动之后会以一倍Beat进行执行器注册, 调度中心以一倍Beat进行动态任务发现;
- “执行器” 在进行任务注册时将会周期性维护一条注册记录,即机器地址和AppName的绑定关系; “调度中心” 从而可以动态感知每个AppName在线的机器列表,具体信息见
xxl_job_registry表。

- 执行器摘除分为主动摘除和过期摘除:
- 过期摘除:注册信息的失效时间为三倍Beat,也就是90s,执行器销毁时,将会主动上报调度中心并摘除对应的执行器机器信息,提高心跳注册的实时性;
- 主动摘除:在WEB页面主动删除执行器。
新建一个任务
新建好执行器后,接下来就是定义一个任务分配给执行器执行。
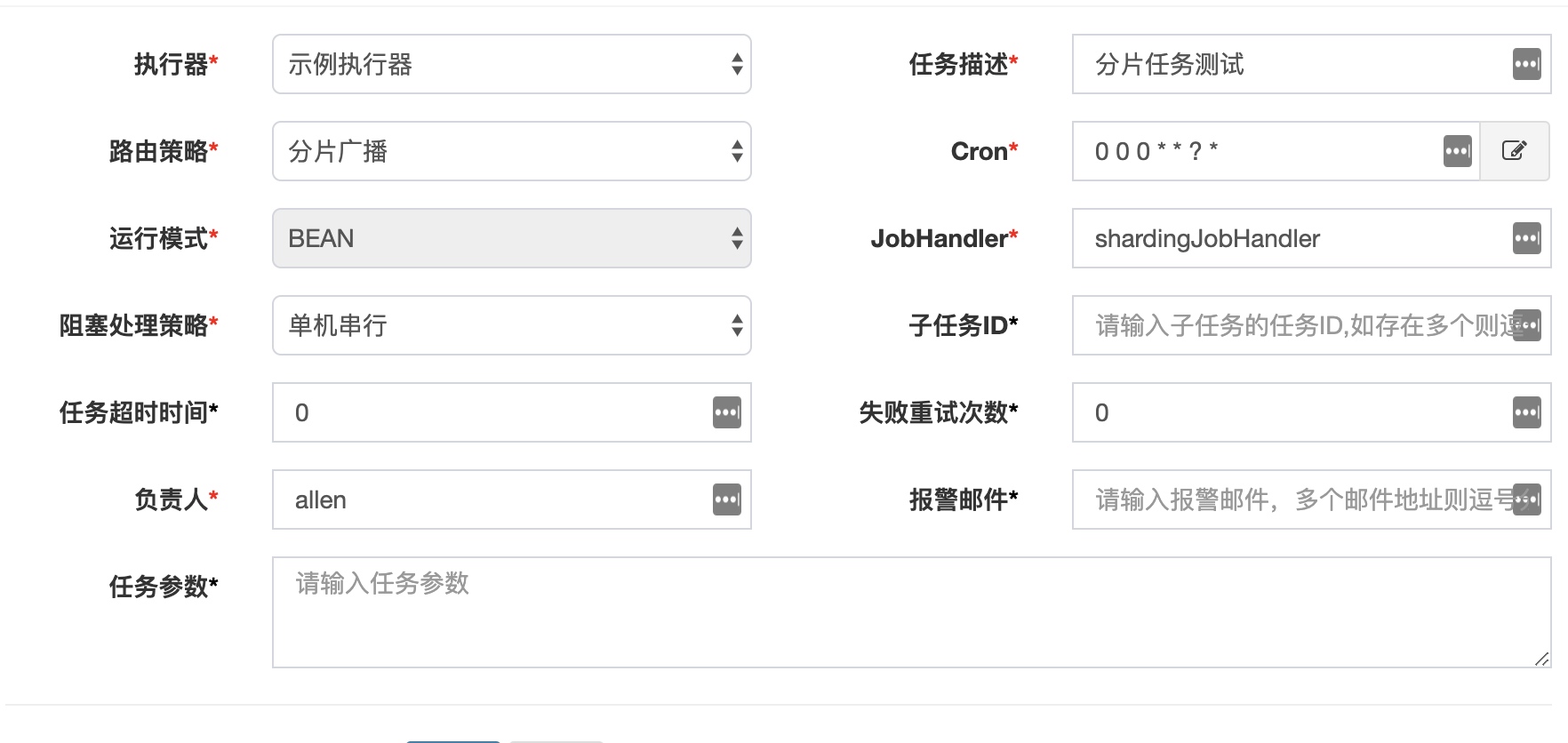
运行模式:Bean模式和Glue模式
如果把业务代码比作奔驰在路上的跑车,如果我们要给轮胎加一个零件,有两种方案,一是把车停下来把零件加上去后再启动,这就是Bean模式,二是不停车,车在跑的同时直接在论坛上把零件「粘」上去,这也是Glue(中文含义就是胶水)的意义来源。
两者区别:
- Bean模式的业务代码保存在执行器,Glue模式的业务代码保存在调度中心,运行在执行器;
- Bean模式更新代码需呀停机,Glue模式支持通过Web IDE在线更新,实时编译和生效;
- Glue模式提供版本回滚功能,Glue模式每次执行前都要判断为最新版本,否则需要冲洗构造任务线程;
- Glue模式支持跨语言,Shell、Python、Nodejs
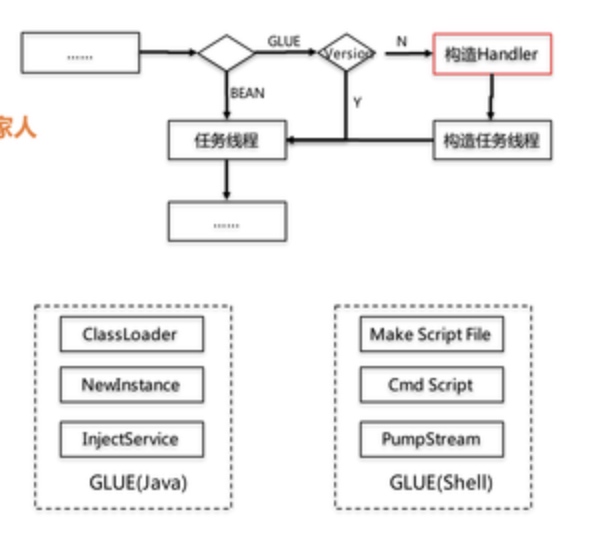
Glue Java 模式是通过 GLUE Class loader 加载源码的方式,加载源码可以注入 spring 当中其他的一些 server 组件,很方便的接触 spring 其他服务。你修改的时候,下次任务执行,会是你当前这份源码重新实例化,注入一些新的服务进行执行。
开发一个JOB
类级别:在XXL-JOB中,所以的JOB都需要继承IJobHandler并重写execute方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| public abstract class IJobHandler {
public static final ReturnT<String> SUCCESS = new ReturnT<String>(200, null);
public static final ReturnT<String> FAIL = new ReturnT<String>(500, null);
public static final ReturnT<String> FAIL_TIMEOUT = new ReturnT<String>(502, null);
public abstract ReturnT<String> execute(String param) throws Exception;
public void init() throws InvocationTargetException, IllegalAccessException {
}
public void destroy() throws InvocationTargetException, IllegalAccessException {
}
}
|
方法级别:前提是Spring容器,直接在方法上添加@XxlJob("demoJobHandler")就行。
无论是类级别还是方法级别,执行方式格式要求为 public ReturnT<String> execute(String param)。
官方提供的几种示例任务
demoJobHandler:简单示例任务,任务内部模拟耗时任务逻辑,用户可在线体验Rolling Log等功能;
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@XxlJob("demoJobHandler")
public ReturnT<String> demoJobHandler(String param) throws Exception {
XxlJobLogger.log("XXL-JOB, Hello World."+param);
for (int i = 0; i < 5; i++) {
XxlJobLogger.log("beat at:" + i);
TimeUnit.SECONDS.sleep(2);
}
return ReturnT.SUCCESS;
}
|
shardingJobHandler:分片示例任务,任务内部模拟处理分片参数,可参考熟悉分片任务;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
@XxlJob("shardingJobHandler")
public ReturnT<String> shardingJobHandler(String param) throws Exception {
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardingVO.getIndex(), shardingVO.getTotal());
for (int i = 0; i < shardingVO.getTotal(); i++) {
if (i == shardingVO.getIndex()) {
XxlJobLogger.log("第 {} 片, 命中分片开始处理", i);
} else {
XxlJobLogger.log("第 {} 片, 忽略", i);
}
}
return ReturnT.SUCCESS;
}
|
httpJobHandler:通用HTTP任务Handler;业务方只需要提供HTTP链接即可,不限制语言、平台;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
@XxlJob("httpJobHandler")
public ReturnT<String> httpJobHandler(String param) throws Exception {
HttpURLConnection connection = null;
BufferedReader bufferedReader = null;
try {
URL realUrl = new URL(param);
connection = (HttpURLConnection) realUrl.openConnection();
connection.setRequestMethod("GET");
connection.setDoOutput(true);
connection.setDoInput(true);
connection.setUseCaches(false);
connection.setReadTimeout(5 * 1000);
connection.setConnectTimeout(3 * 1000);
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("Content-Type", "application/json;charset=UTF-8");
connection.setRequestProperty("Accept-Charset", "application/json;charset=UTF-8");
connection.connect();
int statusCode = connection.getResponseCode();
if (statusCode != 200) {
throw new RuntimeException("Http Request StatusCode(" + statusCode + ") Invalid.");
}
bufferedReader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
StringBuilder result = new StringBuilder();
String line;
while ((line = bufferedReader.readLine()) != null) {
result.append(line);
}
String responseMsg = result.toString();
XxlJobLogger.log(responseMsg);
return ReturnT.SUCCESS;
} catch (Exception e) {
XxlJobLogger.log(e);
return ReturnT.FAIL;
} finally {
try {
if (bufferedReader != null) {
bufferedReader.close();
}
if (connection != null) {
connection.disconnect();
}
} catch (Exception e2) {
XxlJobLogger.log(e2);
}
}
}
|
commandJobHandler:通用命令行任务Handler;业务方只需要提供命令行即可;如 “pwd”命令;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
@XxlJob("commandJobHandler")
public ReturnT<String> commandJobHandler(String param) throws Exception {
String command = param;
int exitValue = -1;
BufferedReader bufferedReader = null;
try {
Process process = Runtime.getRuntime().exec(command);
BufferedInputStream bufferedInputStream = new BufferedInputStream(process.getInputStream());
bufferedReader = new BufferedReader(new InputStreamReader(bufferedInputStream));
String line;
while ((line = bufferedReader.readLine()) != null) {
XxlJobLogger.log(line);
}
process.waitFor();
exitValue = process.exitValue();
} catch (Exception e) {
XxlJobLogger.log(e);
} finally {
if (bufferedReader != null) {
bufferedReader.close();
}
}
if (exitValue == 0) {
return IJobHandler.SUCCESS;
} else {
return new ReturnT<String>(IJobHandler.FAIL.getCode(), "command exit value("+exitValue+") is failed");
}
}
|
路由策略
当执行器集群部署时,提供丰富的路由策略,包括;
- FIRST(第一个):固定选择第一个机器;
- LAST(最后一个):固定选择最后一个机器;
- ROUND(轮询)
- RANDOM(随机):随机选择在线的机器;
- CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
- LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
- LEAST_RECENTLY_USED(最近最久未使用):最久为使用的机器优先被选举;
- FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
- BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
- SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
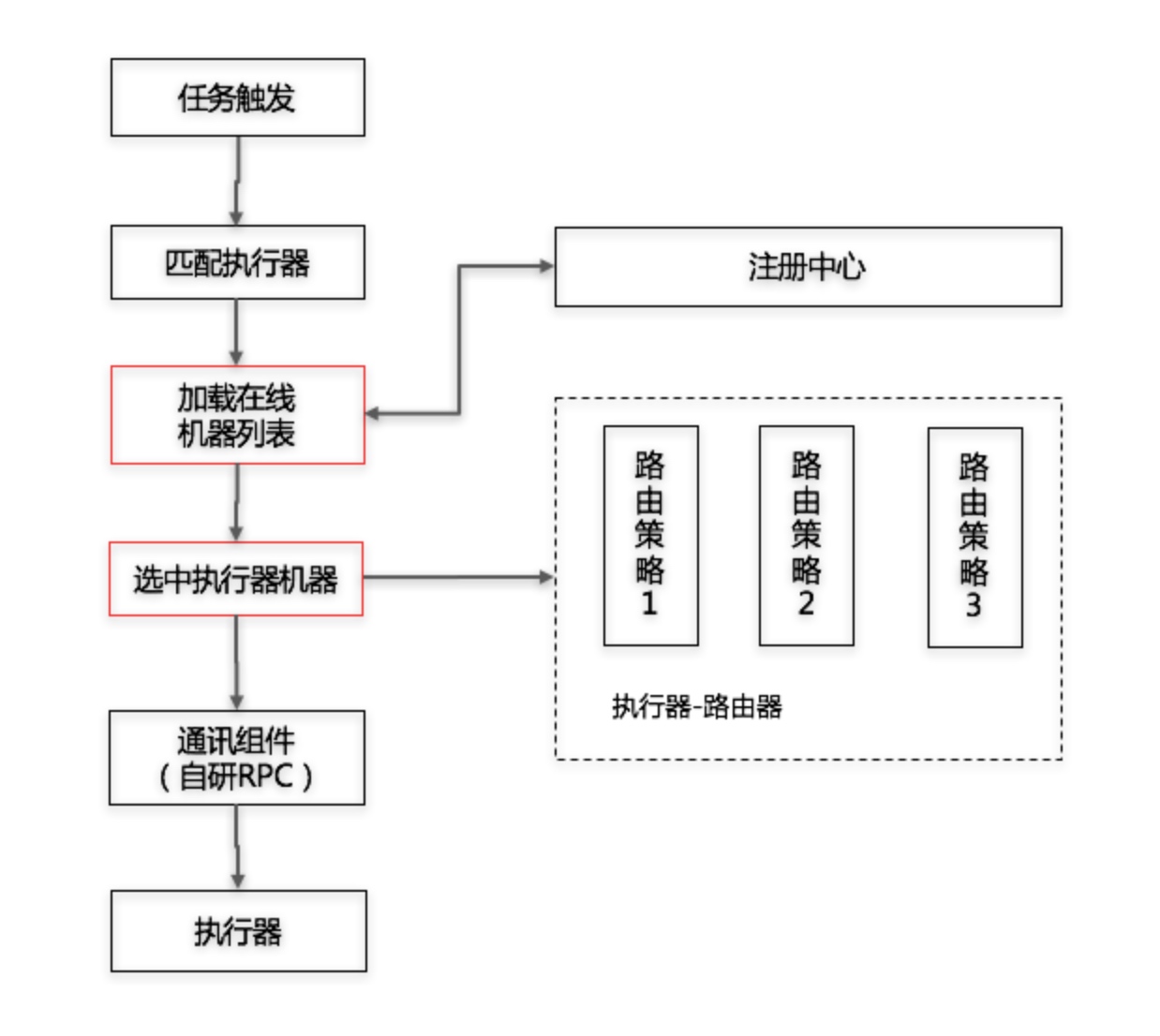
从任务触发到任务执行在调度中心阶段有几个步骤
- 匹配执行器
- 从注册中心加载在线机器节点列表
- 根据路由策略去匹配一组机器
- 通知这个机器去执行任务
基本前面几个路由策略比较容易理解,这里我们着重说一下后面三个路由策略。故障转移和忙碌转移
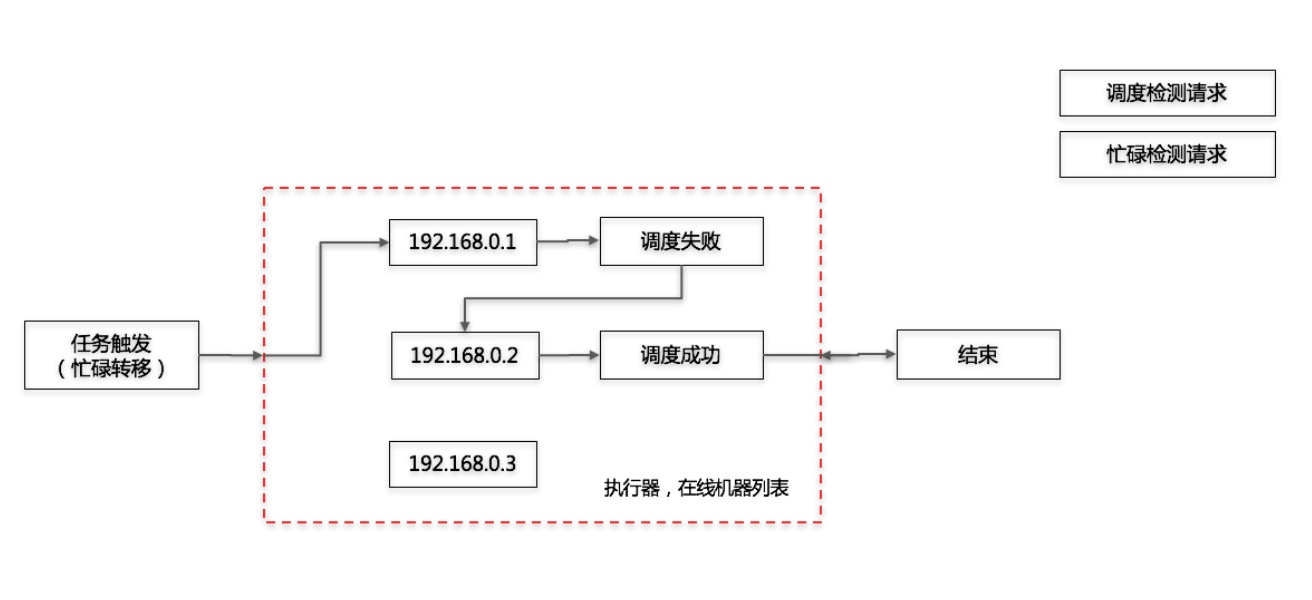
调度器在调度时会请求执行器是否处于处于故障或者忙碌状态,对应着ExecutorBiz的开放出来的两个方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public interface ExecutorBiz {
public ReturnT<String> beat();
public ReturnT<String> idleBeat(int jobId);
}
|
分片广播
有时候一台机器处理不够,需要多台机器分片处理。
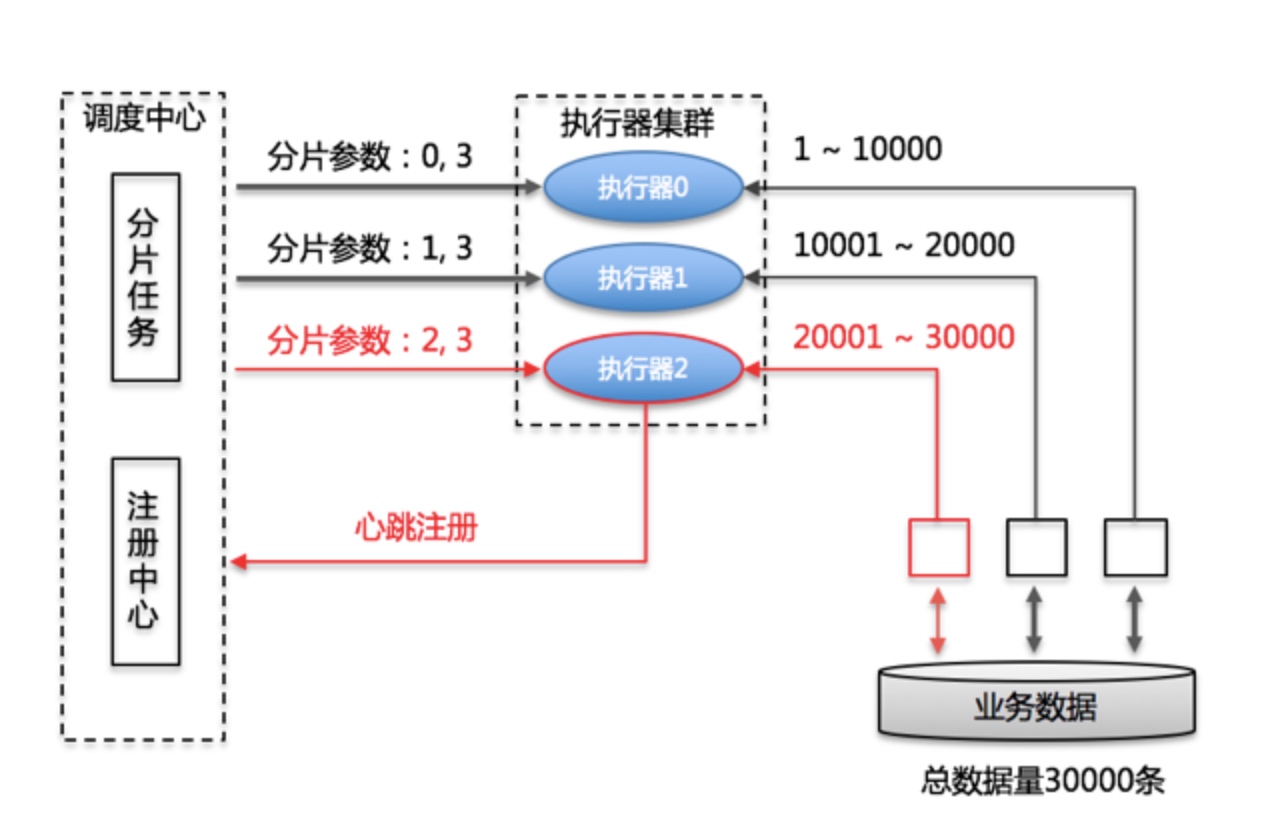
可以参照上面的分片广播任务查看如何使用。
阻塞处理策略
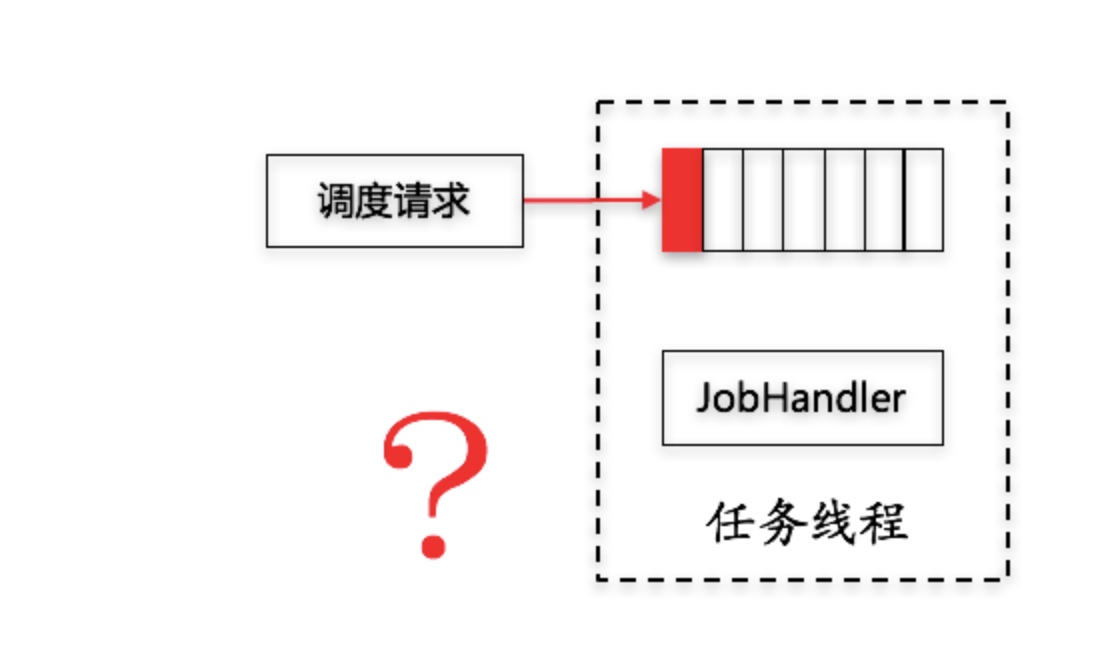
当我们有一些耗时任务,触发的频率超过它的执行器所执行的那些速度的时候,如上图,红色的触发请求进来,但是前面的还在堆积着执行,这时候怎么办?第一条就是默认的单机串行,会把请求入队列,等前面的执行完了之后,挨个把所有的触发的任务全都执行掉。第二个就是丢弃后续的调度,红色的进来了,发现前面已经有了,或者是当前已经 JOB 运行了,直接把后面的标记失败,不进行后面的执行了。最后一个就是覆盖之前调度的,它发现前面队列里面的数据或者任务执行的情况下,把队列清空,把清空的数据全都标记失败,然后把执行的 JOB 也标记失败,让自己来运行。
触发规则
现在提供的触发规则主要有 3 种。
- 第一种是 Cron 表达式,每一个任务需要配一个 Cron 表达式。
- 第二种是任务依赖,你可以为每一个任务配置一个子任务,当副任务执行完成之后,可以触发子任务,这样关联的方式进行触发执行。
- 第三种就是事件触发,其实就是类似于 Mq 的场景,代码里面有一个业务逻辑,触发了一个任务执行。
任务状态
- 成功(SUCCESS)
- 失败 (FAIL)
- 超时 (FAIL_TIMEOUT)
- 进行中
调度日志和任务日志
调度日志:调度平台调度任务的日志,如果任务失败会保留出失败的日志。
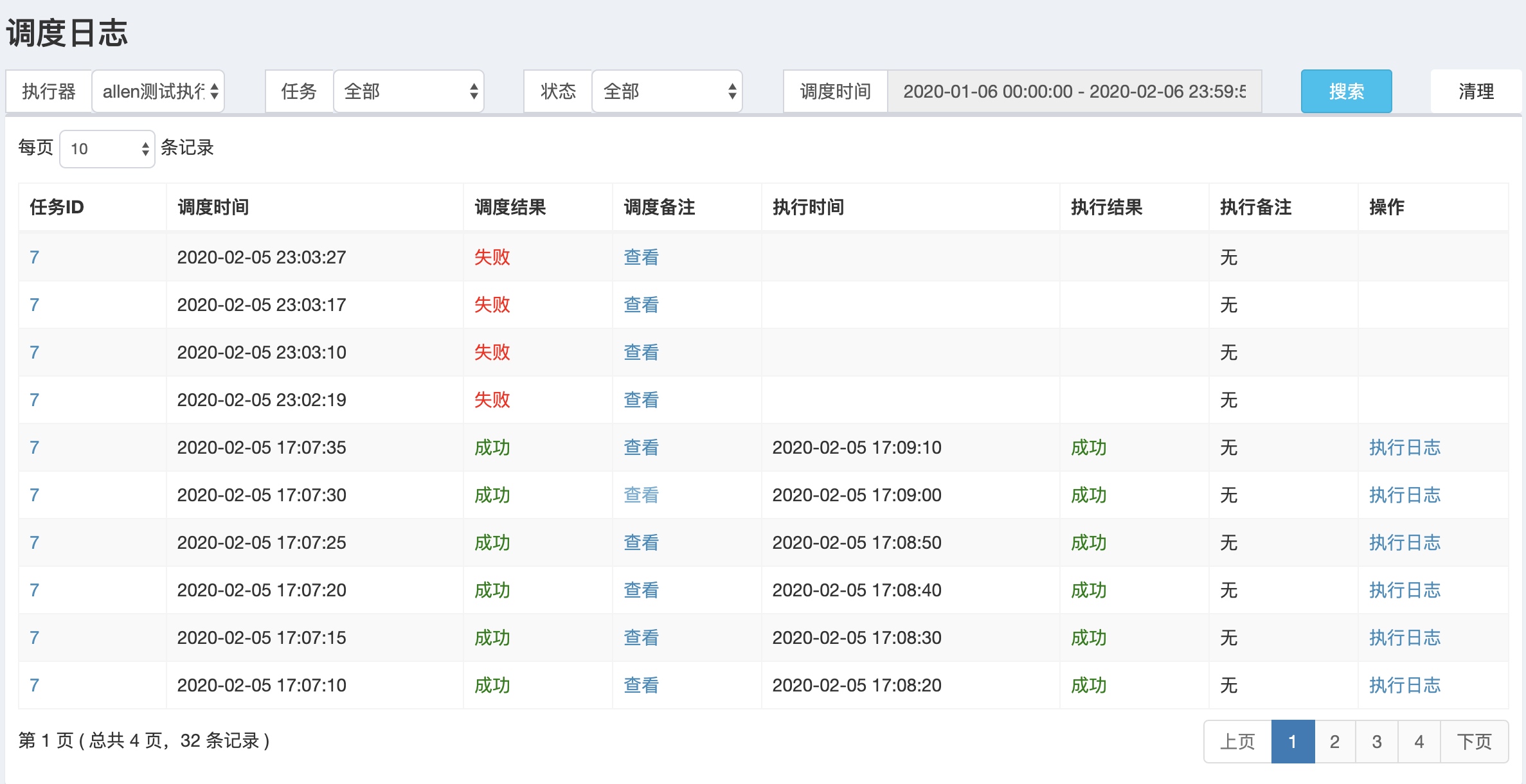
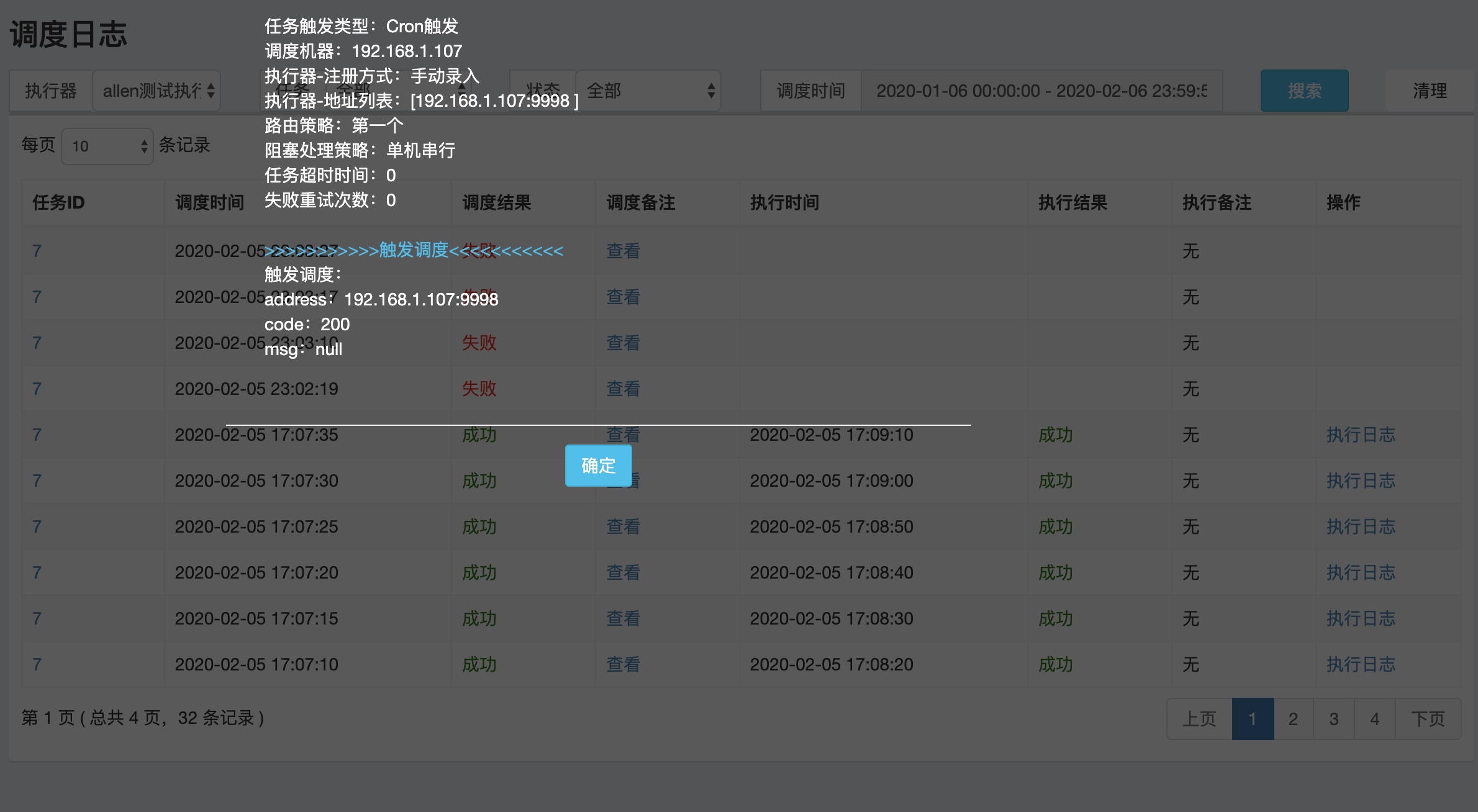
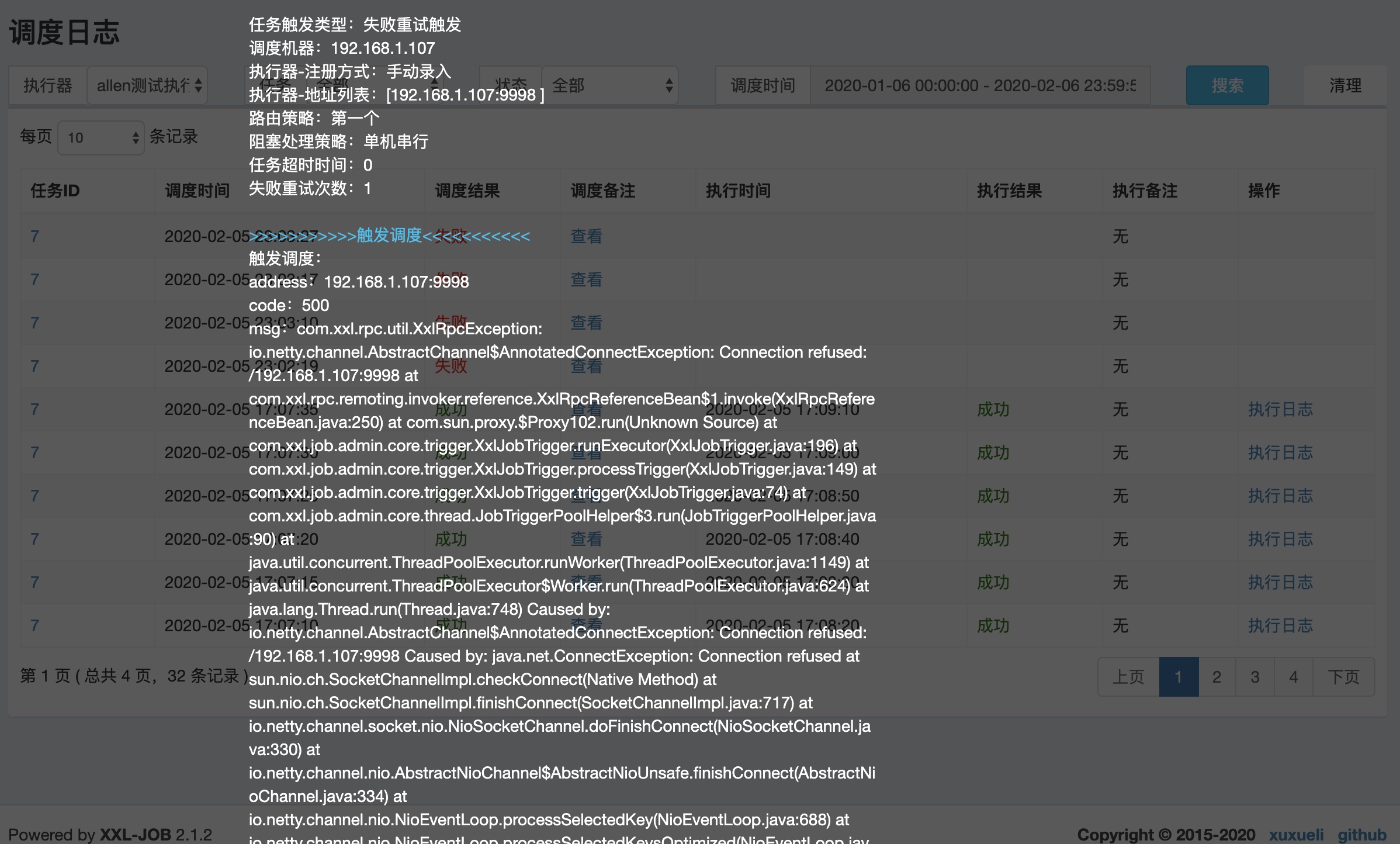
任务日志:具体任务执行的日志,下面那张图是一个日志页面展示(貌似是读不到日志),真实应该展示的应该是下面的日志内容。
1
2
3
4
5
6
7
| 2020-02-05 23:29:54 [com.xxl.job.core.thread.JobThread#run]-[124]-[Thread-6] <br>----------- xxl-job job execute start -----------<br>----------- Param:
2020-02-05 23:29:54 [com.xuxueli.executor.sample.frameless.jobhandler.ShardingJobHandler#execute]-[20]-[Thread-6] 分片参数:当前分片序号 = 0, 总分片数 = 2
2020-02-05 23:29:54 [com.xuxueli.executor.sample.frameless.jobhandler.ShardingJobHandler#execute]-[25]-[Thread-6] 第 0 片, 命中分片开始处理
2020-02-05 23:29:54 [com.xuxueli.executor.sample.frameless.jobhandler.ShardingJobHandler#execute]-[27]-[Thread-6] 第 1 片, 忽略
2020-02-05 23:29:54 [com.xxl.job.core.thread.JobThread#run]-[164]-[Thread-6] <br>----------- xxl-job job execute end(finish) -----------<br>----------- ReturnT:ReturnT [code=200, msg=null, content=null]
2020-02-05 23:29:55 [com.xxl.job.core.thread.TriggerCallbackThread#callbackLog]-[190]-[xxl-job, executor TriggerCallbackThread] <br>----------- xxl-job job callback finish.
|
用户管理
两种角色:
- 管理员:拥有所有的执行器的权限
- 普通用户:由管理分配指定的执行器的权限
目前发现的几个小问题
报表页面统计简单
运行报表页面只有任务数量、调度次数、执行器数量的统计,无法根据不同执行器展现特定执行器的数据报表。不同用户的报表页面数据没有隔离
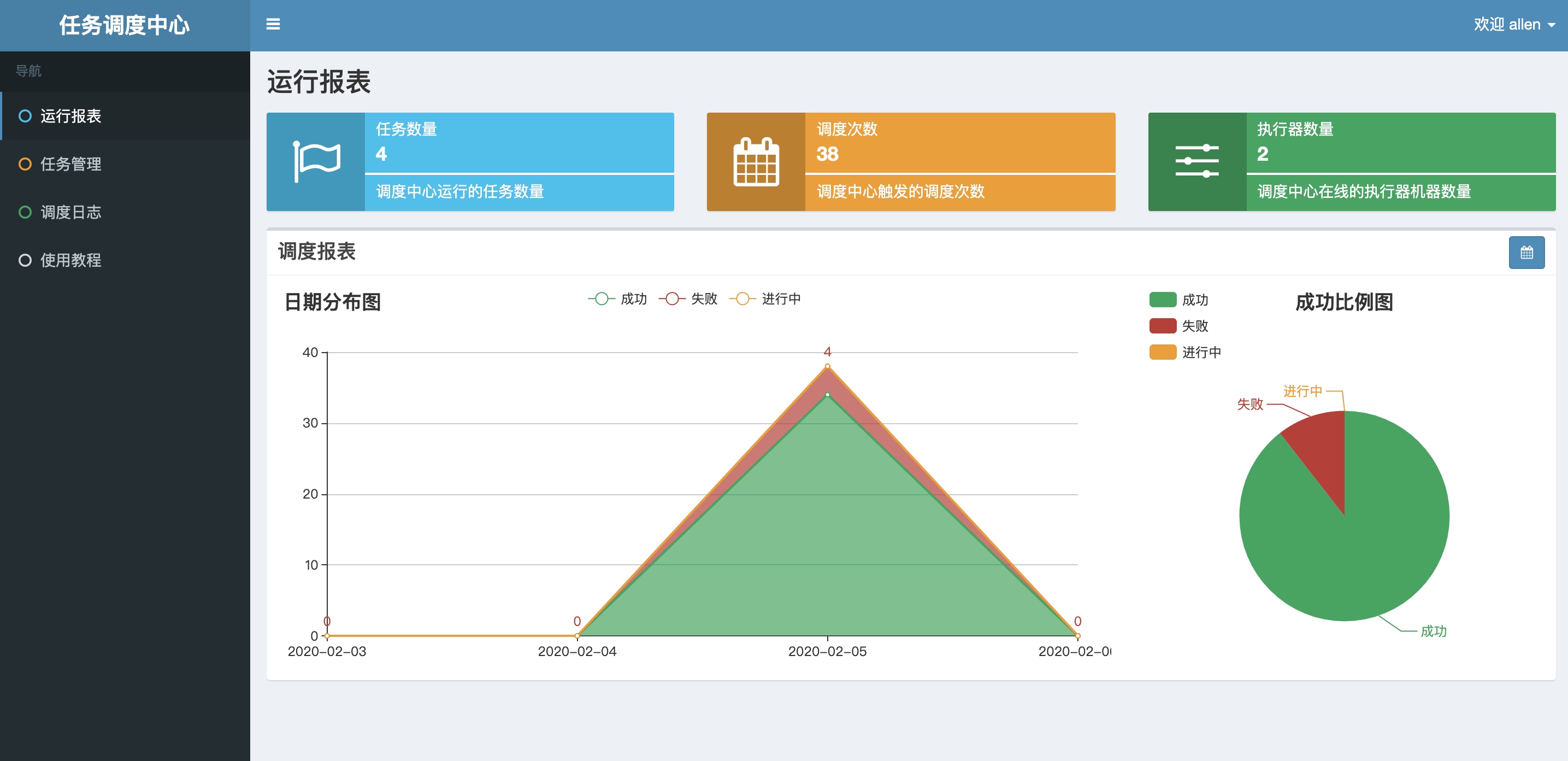
对于allen用户,报表页面的数据和管理员登录后所展示的数据一样。
但执行器管理和任务管理以及调度日志,是做了数据隔离的。
手动输入执行器总显示Online
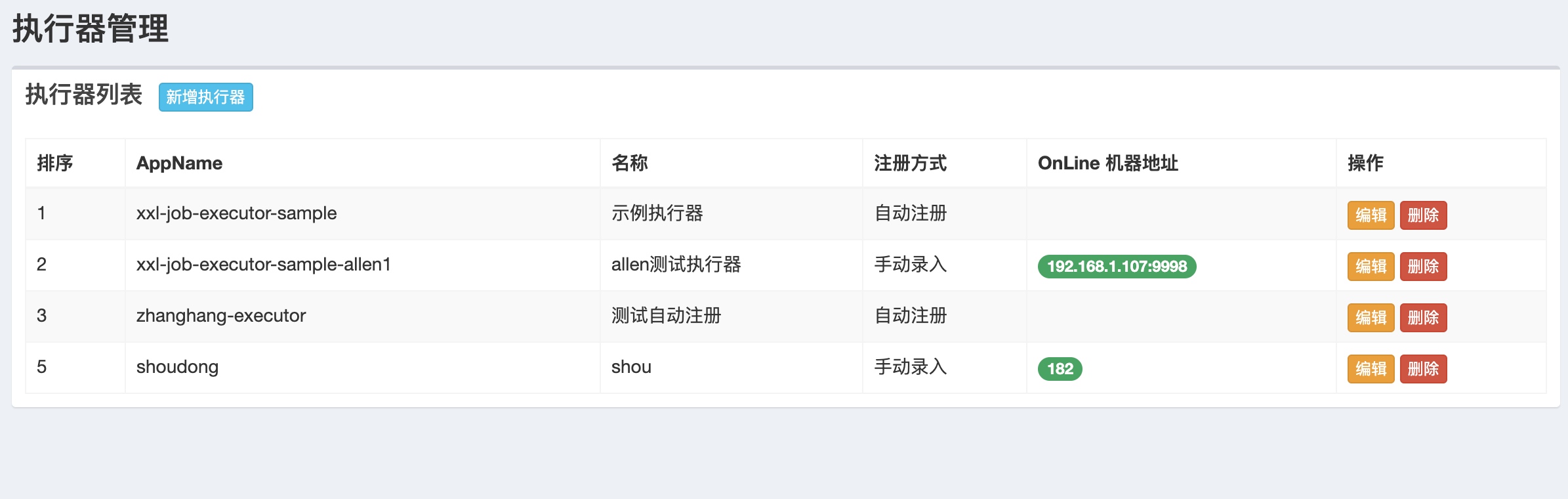
对于手动录入的执行器,总显示Online。
这样的好处是,用户可以手动控制上线的机器,只要修改机器列表即可。
是否可以覆盖需求
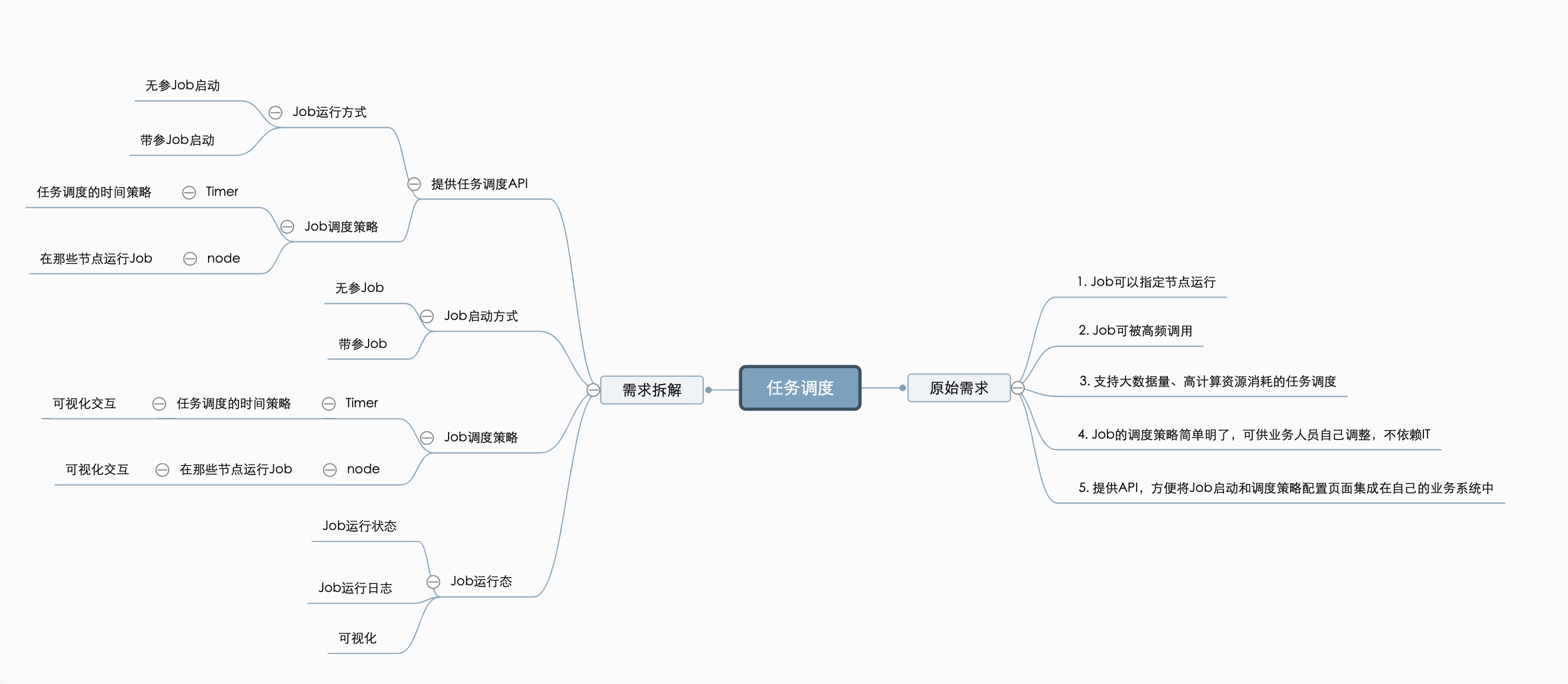
- 是否可以指定节点运行?
A:XXL-JOB运行的基本单位是一个执行器集群,但是可以通过指定不同的路由策略达到指定机器节点的目的。
- JOB可以被高频调用
A:参照压测报告
XXLJOB有过持续20小时,80W次调度100%成功率的测试报告。
- 支持大数据量的任务调度
A:XXL-JOB支持分片广播,是支持大数据量的任务调度的,数据量的多少应该取决于执行器集群的数量吧
- 调度策略简单明了?
A:简单明了
- 提供API
API接口
提供了调度中心和执行器的API。