很早就了解过SPI的概念,刚开始知道是看JDBC驱动实现的时候发现有用到,后面陆陆续续发现在Dubbo中也有Dubbo SPI的概念,希望可以把自己的理解和困惑记录下来。
SPI解决了什么问题?
一种技术的产生必然有其产生的原因,如果现有的技术可以满足解决,就不会出现一种新的解决方案。简单来说,Java SPI实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制。简单理解,既然策略模式可以解决,为什么还要SPI呢?这里举一个例子。
1 | interface Pay{} |
对于支付方式来说,目前市场上有2种主流的支付方式。公司目前使用的是支付宝,突然有一天,老板接受了一篇专访,结果马爸爸骂老板是“三姓家奴”,老板一怒之下把支付宝给下了,改用微信支付。这时,对于开发者来说的改动看起来简单只是new 一个新的实现而已。
直接改动原来的代码不是说不可以,只是违背了开闭原则的设计原则,对扩展开发,对修改关闭。换一个角度,你永远无法直接需求会怎么变动,万一哪天老板要求改回来怎么办。
SPI的实现原理
对于上一节的例子,可以采用SPI的方式,具体Java SPI的使用这里不做过多解释。可以简单看下JDBC中的例子。
1 | ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class); |
在进入代码之前,我们可以猜测一下实现方式如何。在功能表象而言,SPI提供的能力其实就是在应用的运行期,加载并实例化 META-INF/services配置中定义的类。
进入load方法发现也差不多,这里给出关键的代码片段。
1 | private boolean hasNextService() { |
JDBC中的SPI机制
JDK制定了JDBC规范,落实到代码层面可简单认为JDK提供了JDBC interface接口,各个数据库厂商根据这一份规范做各自的实现。当我们需要使用MySql时,就可以引入相应的依赖,同时找到MySql的实现去使用,正好符合SPI 的应用场景。
简单分析一下,JDBC的SPI的使用逻辑。入口在conn = DriverManager.getConnection(url, username, password);,当执行到这一句代码时,会触发DriverManager的加载和初始化,进入DriverManager可以看到下面的static的静态代码块,我们知道JVM在加载类时会触发static代码块的执行。
1 | /** |
从代码块的注释可以看出,loadInitialDrivers() 做的事情仅仅是加载初始化的JDBC驱动,这里会首先去检查系统配置中的jdbc.properties配置,之后再会使用ServiceLoader去加载。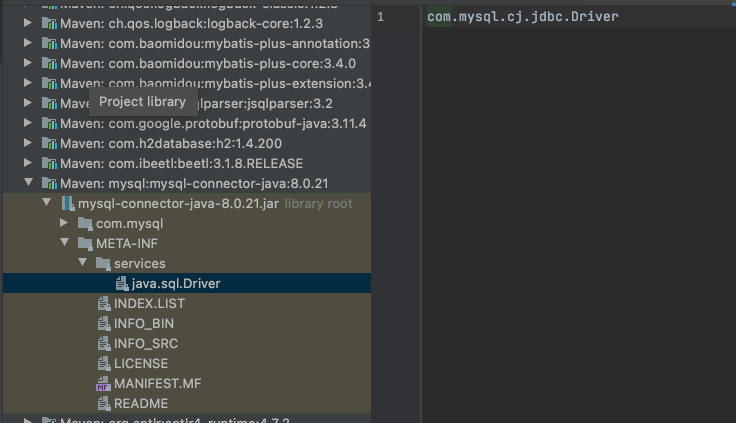
可以看到,具体的实现类为com.mysql.cj.jdbc.Driver,也就是说此时会触发com.mysql.cj.jdbc.Driver的加载初始化,我们在看一下com.mysql.cj.jdbc.Driver的代码。
1 | public class Driver extends NonRegisteringDriver implements java.sql.Driver { |
com.mysql.cj.jdbc.Driver 的做的事情非常简单,就是把自己注册到DriverManager中,注意,此时com.mysql.cj.jdbc.Driver 可以看作已经完成了加载初始化,并new出了一个实例注册到了DriverManager中。依旧从conn = DriverManager.getConnection(url, username, password);的方法可以看到DriverManager是如何使用registeredDrivers的,从注释中可以看到会从已注册的registeredDrivers逐个尝试进行一次连接,拿到正确的Connection就返回。
1 | // Walk through the loaded registeredDrivers attempting to make a connection. |
另外多提一点,Java SPI在这里还打破了类的双亲委托机制。我们知道,JVM在加载类时,会遵循双亲委托机制,同时对于一个Class而言,其中的依赖类也会使用加载该Class的类加载器去加载。比如说,Class A 中有一个 Class B的依赖,在JVM 加载 A时,假如用的是启动类加载器,此时也只能用启动类加载器去加载B (前提是 B 还没被加载到JVM中,我们知道JVM在加载Class时首先会检查该Class是否已经加载到JVM中,如果没有被加载,则使用双亲委托机制去加载)。为什么这样做呢?反面去想的话,如果A是启动类加载器加载的,A必定属于JDK的核心类,倘若A中的依赖不由启动类加载器去加载,而使用应用类加载器去加载,此时如果此时在应用目录伪造一个 核心的类 ,比如说Object类,让应用类加载器去加载Object类到JVM,此时必定带来安全的风险。
那么类比于JDBC,DriverManager 属于JDK的核心包,可知加载DriverManager必定是启动类加载器,那么DriverManager中的依赖应该也是由启动类加载去加载,但我们知道Driver接口的实现类是第三方厂商自定义的,这些实现类必然不会被启动类加载器去加载。怎么解决这个问题呢?只要启动类加载器加载DriverManager时,提前把第三方厂商实现的Driver实现类加载到JVM中就行。所以在DriverManager 的static静态代码块中的loadInitialDrivers()的做事情就是提前加载。
RPC框架、可扩展性
在后续看Dubbo 和 soft-rpc等 RPC框架中,发现均存在类似SPI的设计,例如Dubbo自己实现类一套Dubbo SPI的机制,比Java SPI更加优雅,并且可以做到按需加载。
这里引用何小锋老师的一段解释:
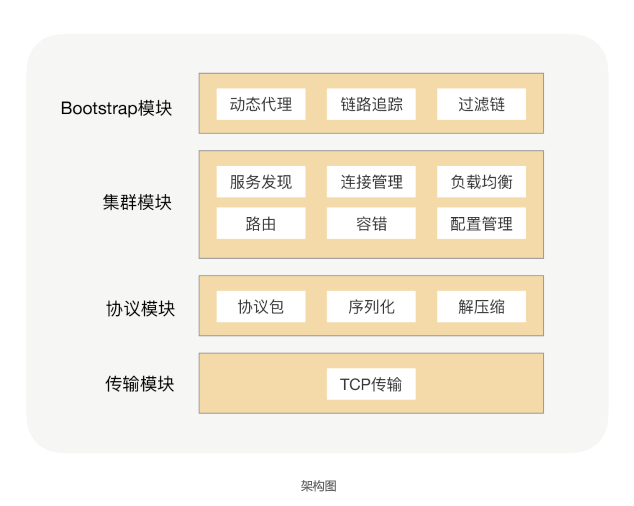
在 RPC 框架里面,我们是怎么支持插件化架构的呢?我们可以将每个功能点抽象成一个接口,将这个接口作为插件的契约,然后把这个功能的接口与功能的实现分离,并提供接口的默认实现。加上了插件功能之后,我们的 RPC 框架就包含了两大核心体系——核心功能体系与插件体系
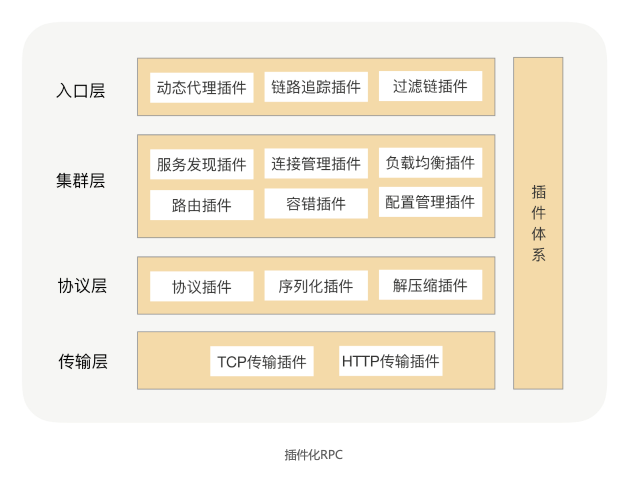
这时,整个架构就变成了一个微内核架构,我们将每个功能点抽象成一个接口,将这个接口作为插件的契约,然后把这个功能的接口与功能的实现分离并提供接口的默认实现。这样的架构相比之前的架构,有很多优势。首先它的可扩展性很好,实现了开闭原则,用户可以非常方便地通过插件扩展实现自己的功能,而且不需要修改核心功能的本身;其次就是保持了核心包的精简,依赖外部包少,这样可以有效减少开发人员引入 RPC 导致的包版本冲突问题。
一点个人理解
SPI最大的好处就是,对于使用方(调用方)而言,屏蔽了变化性,服务的提供方可以动态去提供各种各样的服务(接口实现类),相比于传统的设计,由程序员自己去手动编写静态的代码逻辑去维护这种变化,一方面不符合开闭原则,一方面维护也是一个成本(如果服务很多的话,例如像Dubbo各种各样的SPI接口实现)。
这种可插拔的设计,和Spring IOC设计 很像,变化时只需要改变实现方 使用方可无感知使用,对使用方来说无侵入性。